
2025 年,被称为“Agentic AI 元年”。
2025 年才过去一半,Agentic AI 已经从研究走向工程化,从单体走向多 Agent 协作,从云端走向本地系统级落地。同时,“数字劳动力”也悄然被 AI 智能体引入现实。
AI 智能体(AI Agent)让 AI 能够像人类一样完成任务、像团队一样协同工作、像助理一样主动服务。它正在重新定义各行各业的工作和协作方式,重塑世界的运转方式。我认为,在未来一种全新的协作范式 “人类定义目标,智能体执行路径”,将会成为默认常态。
AI 智能体为什么有这么大的影响力?它的本质是什么?也许大家很轻易就能获取“答案”。在 AI 时代,最不愁的就是“获取答案”。但是,就像不能同时戴两块手表一样,面对生成式“答案”的众说纷纭,哪一个才是对的?或者说更接近对的?如何在 AI 面前保持清醒而准确的判断力,这将是未来的一大课题(Emm… 扯远了,回归正题)。
我打算通过开发一个智能体,来对 AI 智能体背后的逻辑和运行机制探索一二。
Let’s do it!
一、一些概念
首先,我们需要明确一些概念。
什么是智能体
根据人工智能领域的经典教材和权威文献《Artificial Intelligence: A Modern Approach》, 智能体(Agent)的定义如下:
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
简单讲,智能体(Agent)就是一个能自主感知环境、基于目标做出行动决策的系统。
什么是 AI 智能体
AI 智能体,是基于人工智能技术,例如大语言模型(LLM)、强化学习(RL)、规划推理、工具调用(Tool Use)等,具备自主感知环境、理解上下文、制定计划、调用外部工具、连续行动、与环境和用户互动等能力的系统。
特点
自主感知(Perception)
可主动接收环境输入,如用户指令、上下文、文档、数据流。不被动等待,能感知外界变化或反馈。例如:用户上传 PDF,Agent 自动识别结构并提取摘要。
目标导向(Goal-Driven)
不像传统模型只处理单条输入,智能体围绕一个明确的「目标」开展任务流程,动态推进多步操作。例如:目标是“生成一份调研报告”,它会分阶段查资料、写摘要、整合输出。
思维链条(Reasoning / Planning)
具备多轮推理、任务规划能力,能决定“下一步做什么” 。相关技术: ReAct、Tree-of-Thought、Plan-and-Execute 等。
工具调用(Tool Use)
可灵活调用外部函数、API、数据库、搜索引擎、代码解释器等工具。这一特征是 AI 智能体从语言模型向“行动体”进化的关键。
记忆系统(Memory)
通过短期/长期记忆机制维护上下文状态,使对话更连贯,行为更智能。例如:可记录用户偏好、过往任务、事件状态等。
多 Agent 协作(Multi-Agent Collaboration)
多个智能体之间可以分工协作、对话协调,构成 Agent Graph、团队式工作流,解决更复杂任务。例如:一个知识采集 Agent + 写作 Agent + 审核 Agent 联合生成报告。
反思与自我优化(Self-Reflection)
执行完任务后能自检过程和结果,发现错误并修正,或优化下一轮行为。例如:AutoGPT 的任务循环中,会根据执行结果判断是否偏离目标,进行修正。
持续运行与自治(Autonomy & Looping)
支持连续运行、自主决策,减少人工干预,甚至可以触发自己的下一次运行(如 AutoGen、CrewAI、OpenDevin 等)。例如:每天定时自动收集行业资讯、总结趋势并发送报告。
什么是 RAG
RAG(Retrieval-Augmented Generation,检索增强生成),是一种将外部知识库检索与大语言模型生成能力结合的 AI 技术架构,用于解决语言模型上下文长度有限、知识截止时间固定、生成幻觉(hallucination)的问题。
核心思想
先检索,后生成。
在模型生成答案前,先从外部知识库或文档库中检索相关内容,再将这些内容连同用户问题一起送入语言模型,辅助生成更可靠、更符合事实的回复。
RAG 适合知识密集型应用场景。
RAG 系统标准架构
核心流程:用户问题 → 解析意图 → 检索相关知识 → 融合知识与语言模型 → 给出回答
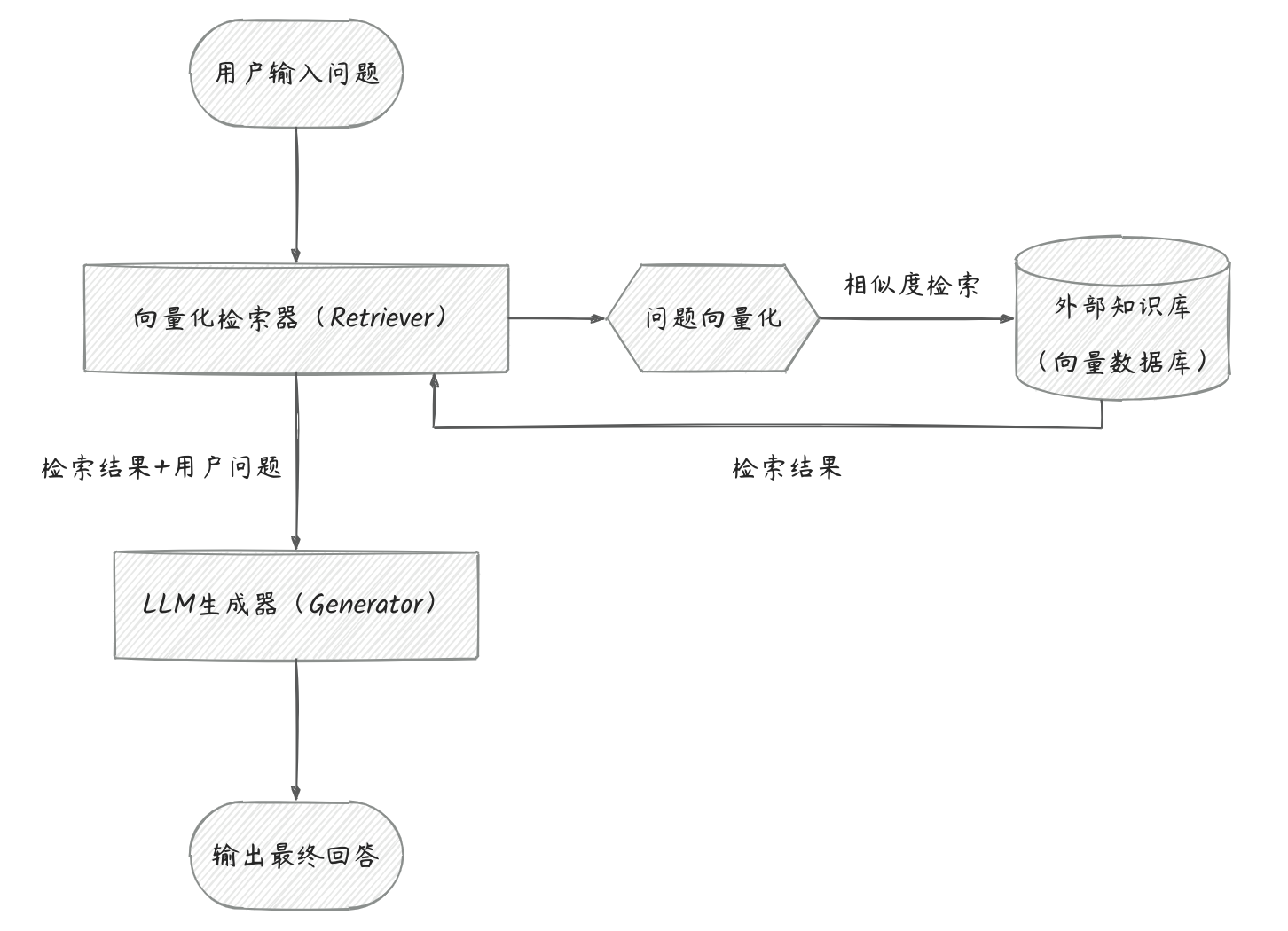
什么是 RAG 智能体
RAG 智能体是现代 AI 智能体体系中的一种知识密集型、多模态增强型智能体形态。
特点
它不仅具备自主决策、环境感知、工具调用等能力,还集成了检索增强生成(RAG)机制。它在执行任务时,能够:
- 自主检索外部知识库
- 融合检索内容和上下文问题进行推理生成
- 根据目标规划行动
- 调用多工具协作完成复杂任务
RAG 智能体标准架构
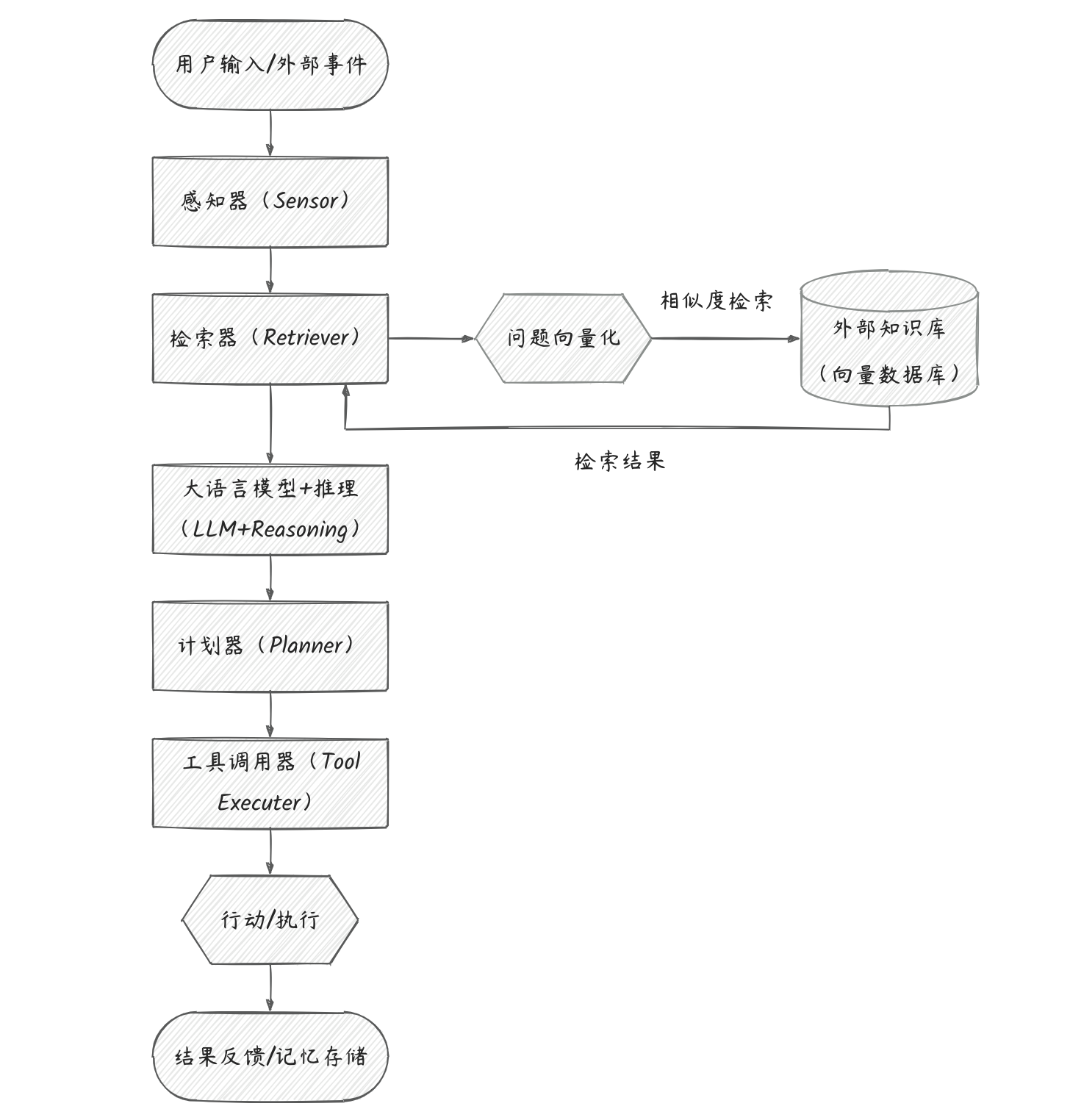
二、搭建 RAG 智能体的途径
途径一:No/Low Code 平台搭建
利用已有的线上平台,如国内的 扣子、智普清言 等,可以免费创建和配置 RAG 智能体应用,有一定免费资源额度,超出需支付费用(例如扣子智能体,按照资源点计费)。适用于无开发经验者,想快速体验智能体功能者,以及通用、简单的小场景。
途径二:开发实现
方式一:利用大模型开放 API,线上调用
可以独立部署,但是需要联网使用(未开源的大模型的 openAPI 需要按 token 收费)。适用于对性能、回答质量要求较高,或者需求复杂、数据敏感等场景。方式二:利用开源模型,本地化离线调用
可以独立部署,并且无需联网,离线可用。适用于个人兴趣研究、对性能无特定要求、预算有限或者行业敏感等场景。
三、开发一个本地化的 RAG 智能体
下面我将从零开始一步一步开发一个离线可用的 RAG 智能体。里面包含了一些值得记录的踩坑填坑过程,或许也能帮助大家更好地理解和尝试开发。
功能清单
✅ 使用本地模型
✅ 支持从文档中提取知识
✅ 支持文档上传、自动构建向量库、多知识库切换
✅ 支持向量化检索(RAG)
✅ 支持 Agent 工具调用
✅ 支持对话记忆(Memory)
✅ 支持历史问答的记录、导出
✅ 支持展示思考过程、停止思考
✅ 友好的 UI 界面
麻雀虽小五脏俱全。
开发基本步骤
AI 智能体应用开发与其他应用开发步骤没有什么太大区别。

需求已经明确(见功能清单),下面我们从技术选型开始。
Step 1: 技术选型
合理的技术选型是你的智能体达到你的预期目标的关键。
开发语言
选型:Python
这个不用多说,整个 AI 生态几乎都是 Python 写的。
智能体框架
选型:LangChain
要开发 RAG 智能体,少不了要进行检索文档、调用大模型、调用工具等操作,这些操作都是最基础的标准动作,已经有开源的框架库帮我们封装好了,不需要我们从头来写。LangChain 在众多开源的智能体框架中,工具链最全,文档完善,社区活跃,生态最大,而且上手难度适中。如果没有特别的要求,LangChain 是不二选择。
注意:从 LangChain v0.1.0+ 开始,为了代码解耦、模块独立性更强,大量原来内置在 langchain 的组件被拆分到了新的包。一般来说,本地化部署,至少还需搭配 langchain-community 一起使用。
文本切分器(Text Splitter)
选型:RecursiveCharacterTextSplitter
文本切分器是构建 RAG 系统时的关键组件,用于把长文本分割成适合向量化与检索的短文本块(chunks)。一个优秀的文本切分器不仅影响检索效果,还能显著提高回答质量。LangChain 框架里就集成了很多个文本分割器工具,本项目选择 RecursiveCharacterTextSplitter,可以按层级字符递归分割,且保留语义。
以下是 LangChain 里集成的文本切分器工具的简单对比:
| 名称 | 分割依据 | 特点 |
|---|---|---|
| RecursiveCharacterTextSplitter | 层级字符(句/段) | 中英兼容,保留语义,支持递归分割,最常用 |
| MarkdownTextSplitter | 标题/段落结构 | 只支持Markdown格式适合文档,保留语义 |
| SpacyTextSplitter | 句子级分割 | 推荐英文,语义好但依赖大模型 |
| NLTKTextSplitter | 句子级分割 | 推荐英文,保留语义,较轻量 |
| TokenTextSplitter | Token 数 | 中英兼容,不保留语义 |
| CharacterTextSplitter | 固定字符数 | 中英兼容,不保留语义,最基础最简单的切割方式 |
文本嵌入模型(Embedding)
选型:HuggingFaceEmbeddings + bge-small-en
嵌入模型用于把文本转成语义向量,让机器可以理解、比较和检索语言内容,是现代语义搜索和 RAG 系统的基础核心。1
嵌入模型 = 语义理解引擎 + 数学向量编码器
其中,向量化编码可将文本内容转成一个固定长度的向量,这些向量位于一个高维空间中,在这个高维空间中,相似内容向量靠得近,不相关内容向量距离远。
由于我们要本地化离线开发,相比线上调用,要多考虑一个维度:平衡本地硬盘资源和模型性能效果,选择方向很明确:开源 + 体积尽可能小 + 性能尽可能高。
几款主流文本嵌入模型:
| 模型名称 | 嵌入维度 | 参数量 | 模型体积(≈) | 所属机构 |
|---|---|---|---|---|
| MiniLM-L6-v2 | 384 | ~22M | 90.9MB | Microsoft |
| bge-small-zh | 384 | ~30M | 95.8MB | BBAI |
| bge-small-en | 384 | ~30M | 130MB | BBAI |
| E5-small | 384 | ~40M | 134MB | Microsoft |
| GTE-small | 384 | ~45M | 67MB | Alibaba |
| bge-base-zh | 768 | ~110M | 409MB | BBAI |
| bge-base-en | 768 | ~110M | 438MB | BBAI |
| E5-base | 768 | ~110M | 438MB | Microsoft |
| GTE-base | 768 | ~110M | 219MB | Alibaba |
| bge-large-zh | 1024 | ~320M | 1.3GB | BBAI |
| bge-large-en | 1024 | ~320M | 1.34GB | BBAI |
| E5-large | 1024 | ~330M | 1.34GB | Microsoft |
| GTE-large | 1024 | ~434M | 670MB | Alibaba |
| SGPT-5.8B | 1024 | ~5.8B | 23.5GB | UKPLab |
本项目选择 bge-small-en(为什么没选 bge-small-zh 后面会讲到),小模型中语义效果最平衡。
bge-small-en 是 BBAI 开源的 BGE 系列模型中的体积较小的一款。BGE 系列模型托管在 Hugging Face 平台,Hugging Face 是 AI 领域最活跃的社区之一,以开放协作闻名。
想要调用 bge-small-en 模型,可以直接使用 LangChain 框架内置的 Embedding 接口封装器 —— HuggingFaceEmbeddings。
注意:LangChain 的 HuggingFaceEmbeddings 实际上是对 sentence-transformers 库的高阶封装,HuggingFaceEmbeddings 包的使用依赖 sentence-transformers 库,安装依赖时需要同时安装 sentence-transformers。
向量数据库(Vector Database)
选型:faiss-cpu
向量数据库是专门用于存储和高效检索向量(如文本或图像的嵌入向量)的数据库系统,是大模型和 AI 应用背后的“语义记忆库”。
本项目选择 Facebook AI Research 团队(FAIR)开源的 FAISS(Facebook AI Similarity Search)。除此之外,Chroma Org 公司的开源向量数据库 ChromaDB 也是不错的选择。
FAISS 有两个可选择的版本:
- faiss-gpu,利用 NVIDIA GPU 进行加速,需安装 CUDA
- faiss-cpu,是 FAISS 库的 CPU-only 版本,适用于 CPU 环境,兼容性好
对于 FAISS 的数据库操作,LangChain 框架也内置了对应的接口封装器 —— FAISS。
本地大模型(LLM)
选型:Ollama + phi3-mini
我们的 LLM 是要本地化调用的,所以需要一个模型引擎来启动本地 LLM 服务。开源社区有不少大语言模型引擎,当中最火的是 Ollama。Ollama 可以让你像运行 Docker 一样在本机调用语言模型。除此之外,它还有以下优点:
- 内置模型仓库(model registry),支持一键 pull 模型
- 兼容 OpenAI API 格式(即很多用 openai.ChatCompletion 写的应用,改一下 API 地址就能跑 Ollama 上的模型)
- Ollama 生态也很不错,目前已支持175个主流大模型。
完整的支持模型列表:https://ollama.com/library
与 Embedding 模型选型一样,LLM 模型同样需要权衡本地硬盘资源和模型性能。
以下为部分 Ollama 支持的主流开源 LLM 模型:
| 模型名称 | 参数量 | 模型体积(量化后) | 所属公司/团队 |
|---|---|---|---|
| LLaMA 3 (8B) | 8B | ~4–6 GB | Meta (Facebook) |
| LLaMA 3 (70B) | 70B | ~30–40 GB | Meta |
| Mistral (7B) | 7B | ~4–5 GB | Mistral AI |
| Mixtral (MoE 8x7B) | 12.9B | ~12 GB | Mistral AI |
| Phi-3 Mini | 3.8B | ~1.8 GB | Microsoft |
| Phi-3 Medium | 14B | ~5–6 GB | Microsoft |
| Gemma (2B) | 2B | ~1.5–2 GB | Google DeepMind |
| Gemma (7B) | 7B | ~5–6 GB |
本项目选择体积相对较小的 phi3-mini,它是微软推出的轻量级开源大模型,属于 Phi 系列模型。定位:轻量级、高性能,适用于移动端和边缘设备。
这是 Phi-3 系列模型在“模型质量 vs 参数规模”维度上的性能表现:
Phi-3-mini(3.8B)质量表现 70,比 LLaMA-3-8B-In 评分高,体积还更小。
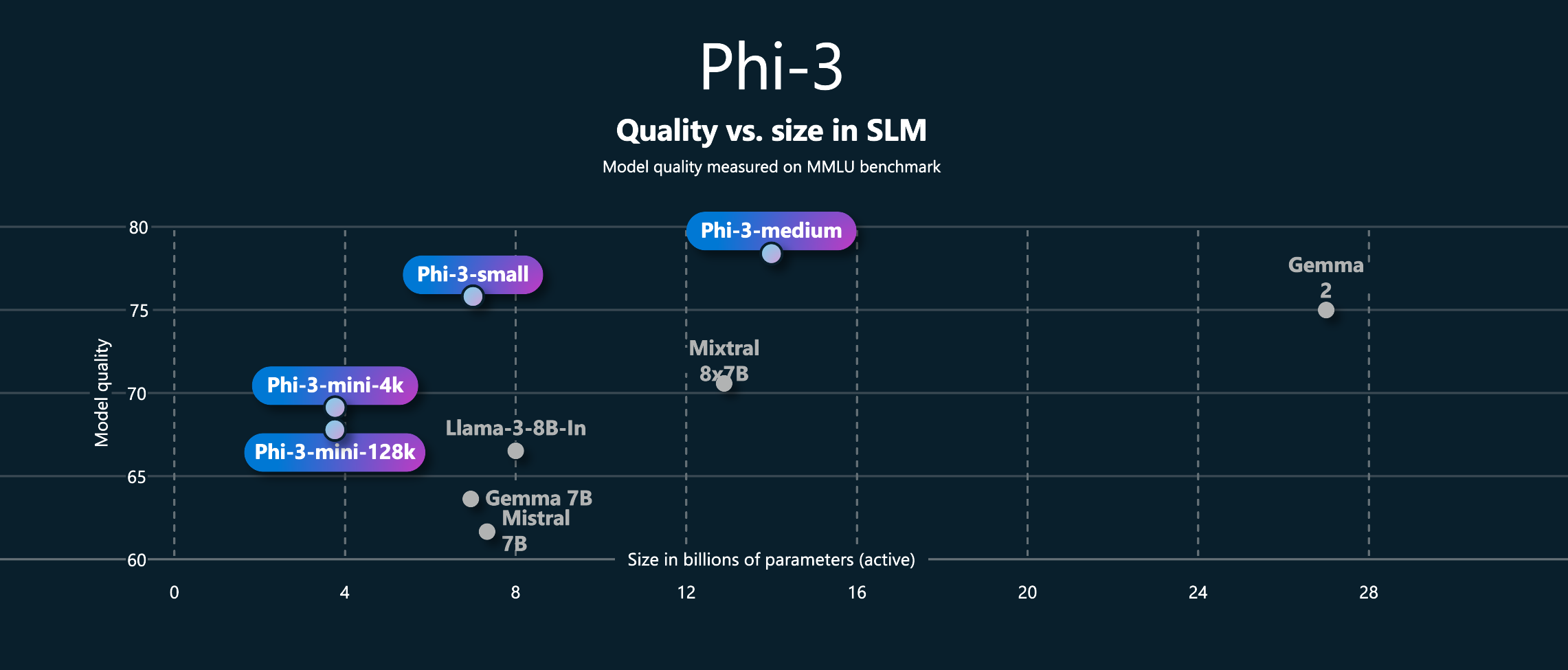
横轴(X 轴):模型大小(Size),单位是 参数量(以 B = Billion = 十亿计)
纵轴(Y 轴):模型质量(Quality),来自 MMLU(多任务语言理解) Benchmark,数值越高表示模型表现越好
Phi 系列模型技术特点:
- 基于 Transformer 架构,参数量较小(Phi-3-mini 约38亿参数)。
- 强调 高效推理 和 低资源消耗,适合本地部署。
WEB 框架
选型:Streamlit
为了把精力集中放在 AI 智能体的逻辑上,本项目前端界面和交互选择使用 Streamlit 框架。Streamlit 的定位是零前端,快速原型,面向数据科学和 AI/ML 工程师的开源 Python 框架。只需几行 Python 代码即可实现展示图表、添加交互控件、部署应用等功能,用于快速构建交互式 Web 应用非常方便,上手也简单。
下面是几款 Python Web 框架对比:
| 框架 | 语言 | 特点 | 适合人群 |
|---|---|---|---|
| Streamlit | Python | 零前端,快速原型,交互控件丰富 | 数据科学、AI 开发者 |
| Flask | Python | 极简 Web 框架,适合小型项目 | Python 工程师 |
| Django | Python | 功能全面,适合大中型系统 | 后端开发者 |
| Dash | Python | 类似 Streamlit,适合数据可视化 | 数据分析 |
| NiceGUI | Python | 基于 Vue3 + TailwindCSS + Python | 全栈视觉化 |
| Panel | Python | 强可视化能力,适合科学计算 | 科研 & 工程领域 |
其他
- 问答链:RetrievalQA 组件
- Agent 工具:Tool 组件
- 对话记忆:ConversationBufferMemory 组件
这些功能组件都已经在 LangChain 中集成。
Step 2: Python 环境搭建
如果已经有本地 Python 运行环境,跳过此步。
Mac 电脑的 Python 环境搭建步骤(Windows 电脑的请自己查一下搞定):
- 安装 Homebrew(Mac和Linux的包管理器,默认不自带)
1 | /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" |
- 安装 pyenv(Python版本管理器)
1 | brew install pyenv |
- 安装 Python
1 | pyenv install x.x.x # Python 版本号 |
推推荐大家安装 3.11 版本,生态比较完备。不建议装太高的版本,我本地版本太高遇到一些坑,后面不得不降级到 3.11。
- 配置 pyenv 环境变量(仅首次)
将以下代码加入 ~/.zshrc 或 ~/.bash_profile:
1 | export PATH="$HOME/.pyenv/bin:$PATH" |
然后执行
1 | source ~/.zshrc # 或 source ~/.bash_profile |
- 设置当前项目用的 Python 版本
1 | cd 项目目录 |
- 创建虚拟环境(可选,推荐)
1 | cd 项目目录 |
激活后,终端前缀会出现 “venv”,表示你当前在这个虚拟环境里。在这个环境里可以直接用 “python” 和 “pip” 命令,而不需要用 “python3” 和 “pip3”。
至此,你的 Mac 的 Python 环境就 ready 了。
Step 3: 项目依赖安装
三方库安装
有人会说,直接告诉我项目依赖清单,然后 pip install -r 不就好了,为什么三方库安装还要拿出来单独说?
因为,项目依赖的安装,大概是我在整个项目中遇到挫折(坑)最多的一步。
坑1:安装 faiss-cpu
首先,经过上面的技术选型,项目核心依赖的三方库也就确定了:langchain、faiss-cpu、streamlit、langchain-community、sentence-transformers。很简单,pip install 一个一个安装,结果到 faiss-cpu,卡壳了。
首先是提示缺少 swig:
1 | error: command 'swig' failed: No such file or directory |
查了下,因为 faiss 本身是 C++ 实现,安装时首先会通过 swig 生成 Python 扩展作为 Python 和 C++ 之间的桥接,现在缺少 swig 这个工具。这个好办,安上便是:
1 | brew install swig |
继续安装 faiss-cpu,换来一堆更大的报错,提示编译缺少 C++ 头文件(截取2行做代表) :
1 | faiss/faiss/python/swigfaiss.i:952: Error: Unable to find 'faiss/MatrixStats.h' |
当 pip 没有成功拉取到 wheel 文件时(可能网络超时、无对应版本的 wheel 等原因),会自动 fallback 到源代码仓库,拉取 tar.gz 源码包来构建安装。但是 pip 只下载了 Python 绑定部分,源码不完整,缺少 C++ 头文件,于是编译报错。如果要继续编译,就要想办法下载完整源文件,可能还要再安装 cmake 等编译工具,然后再尝试。。。好像一条不归路。我们还是不要在 mac 上编译 faiss 源码了,依赖复杂,坑多。
解决办法
换个思路,pip 拉源码编译,是因为没有获取到预编译 wheel,那我是不是可以手动下载官方编译好的 faiss-cpu wheel 文件,让 pip 直接读取本地 wheel 来安装,绕过本地编译。
为了下载更快,特地找了清华源镜像地址:
https://pypi.tuna.tsinghua.edu.cn/simple/faiss-cpu/
注意 wheel 文件要跟本地的 Python 版本对应,比如我是 3.13,就要是 cp313:
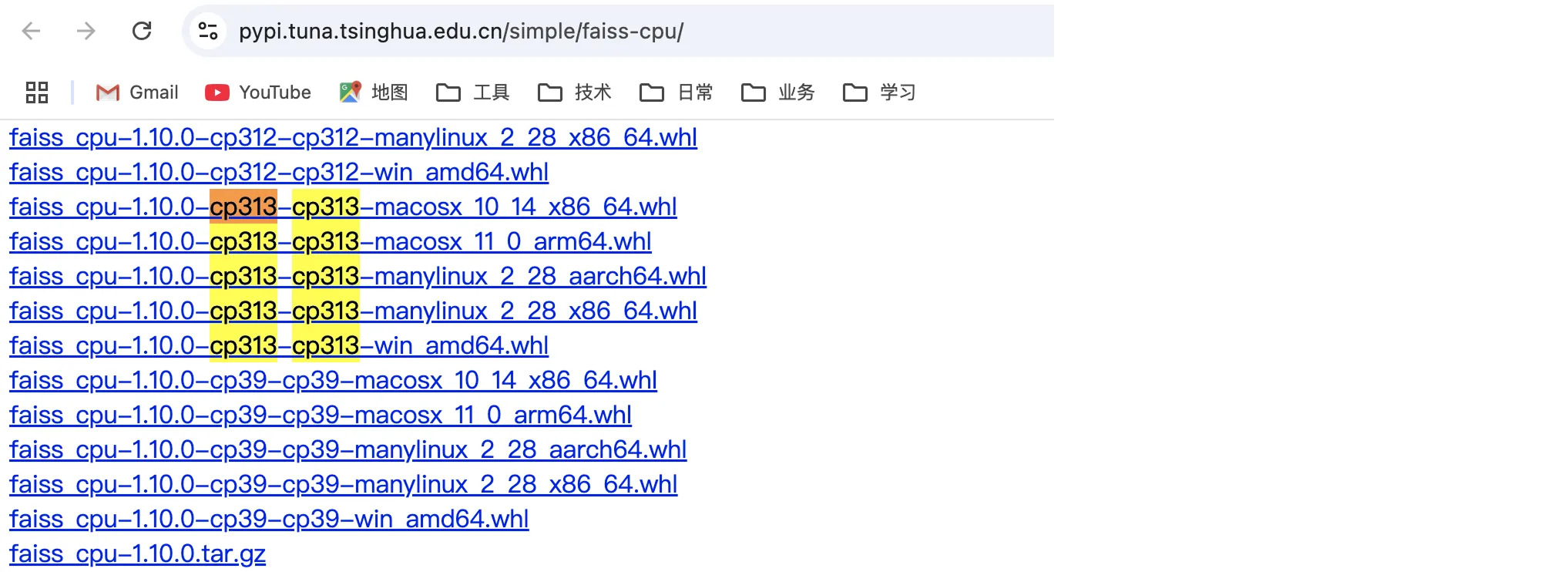
把它下载好放在项目目录下,执行命令
1 | pip install --no-deps ./faiss_cpu-1.10.0-cp313-cp313-macosx_10_14_x86_64.whl |
丝滑安装。
结论
faiss-cpu 不要直接 pip 安装,建议先手动下载本地 Python 对应版本的 wheel 文件再 pip 安装。
坑2: 安装 sentence-transformers
同样,直接安装一堆报错:
1 | ERROR: Cannot install sentence-transformers==0.1.0, |
提示依赖包 torch 版本冲突,看了下,本地没有 torch。好办,pip 安装,but:
1 | pip install --upgrade torch --index-url https://download.pytorch.org/whl/cpu |
为了避免网络超时,我还特意指定了 cpu-only 的 wheel 包地址,结果还是提示找不到 torch。打开 wheel 包地址进去搜索,还真是没有 cp313 macos x86 版本。最高支持 Python 3.11。。。
解决办法
降版本。先是本地 Python 从3.13 降到 3.11(用 pyenv 倒也还方便),然后是重新安装前面所有的依赖,faiss-cpu 则重新下载 cp311 版本,为了不再出幺蛾子,torch 我也直接下载了 cp311 的 wheel 文件(体积不小,有 150 M)。
1 | # 用 pyenv 下载并切换 3.11 版本 |
这回挺顺利。
总结
- 很多主流 AI 库还没出 Python 3.13 及以上 的官方 wheel,pip 就自动 fallback 到源码装,而 faiss 源码依赖超多,Mac 上编译麻烦得很,容易各种编译失败。所以建议大家本地 Python 安装 3.11 版本,各方面生态都支持的比较好。还有遇到源码编译报错的包,推荐手动下载 wheel 安装。
- LangChain 的文本嵌入模块 HuggingFaceEmbeddings 会有层层依赖,安装时容易受挫,别怕,都给你梳理好了:HuggingFaceEmbeddings 依赖 sentence-transformers,sentence-transformers 依赖 torch,(torch 依赖 numpy,运行时才会暴露)。
陆续又增加了些依赖包,最终:
| 包名 | 用途 |
|---|---|
| langchain | Agent 框架,核心库 |
| faiss-cpu | 本地向量库 |
| streamlit | 构建前端聊天界面 |
| langchain-community | LangChain 社区版扩展(内置 FAISS、Huggingface Embedding 等) |
| sentence-transformers | HuggingFaceEmbeddings 的底层依赖,必须安装 |
| torch | sentence-transformers 底层依赖,必须安装 |
| numpy | 数值计算基础库,torch 的依赖,需注意版本对应 |
模型下载
Embedding 模型
bge-small-en 托管在 Hugging Face 平台上,传送门
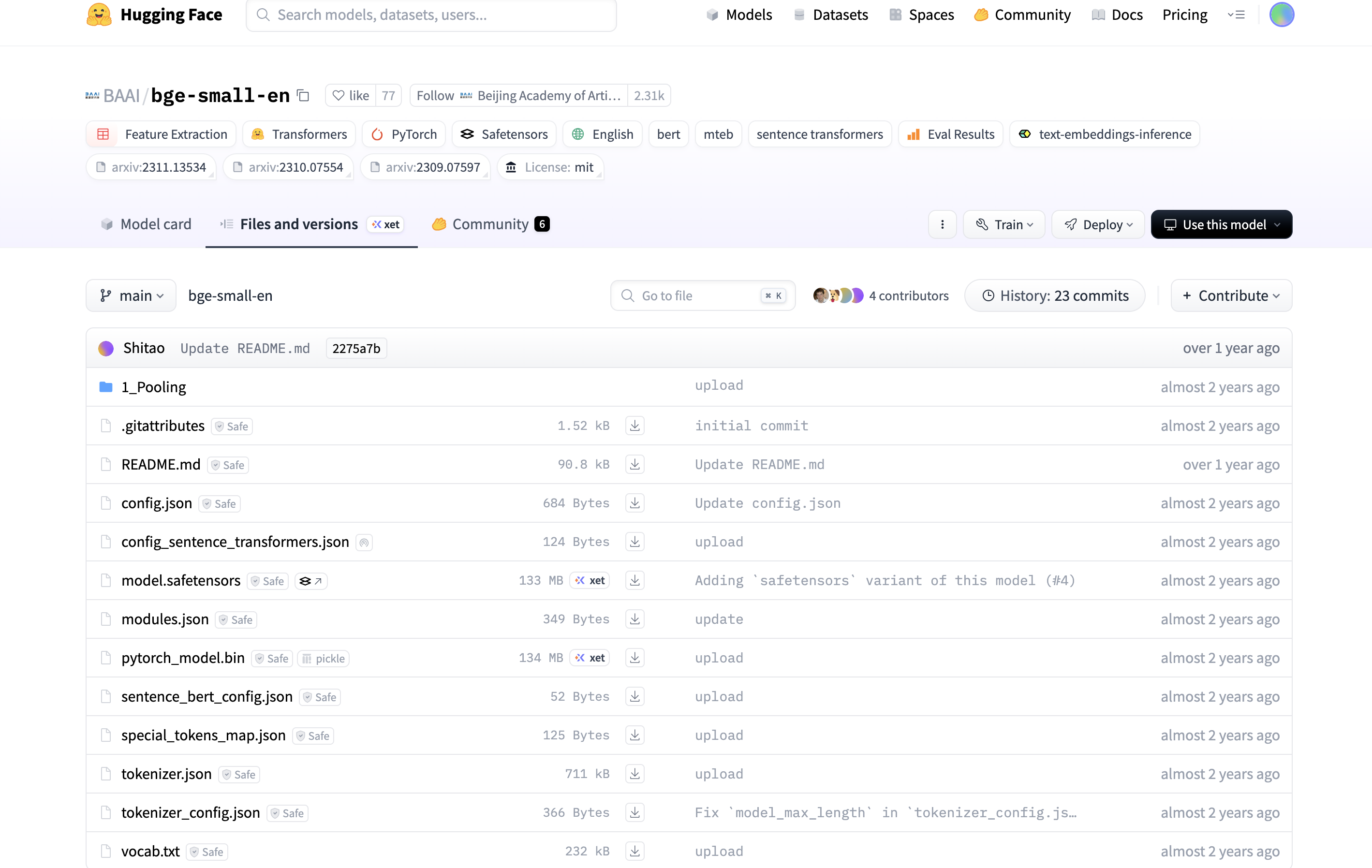
把 main 分支下的文件全部下载下来,放到项目目录下。
坑3:.bin 模型权重文件的加载对 torch 版本有要求
这是后面运行时的报错,因为问题与模型和 torch 密切相关,也一并放在模型这里讲了1
2ValueError: Due to a serious vulnerability issue in torch.load, even with weights_only=True, we now require users to upgrade torch to at least v2.6 in order to use the function. This version restriction does not apply when loading files with safetensors.
See the vulnerability report here https://nvd.nist.gov/vuln/detail/CVE-2025-32434
从 transformers v4.43+ 开始,因 CVE-2025-32434 漏洞,凡是用 torch.load 加载 .bin 模型权重文件(pytorch_model.bin)都会强制要求 torch>=2.6,否则直接 ValueError。
解决办法
要么升 torch 版本,要么模型权重文件换成 safetensors 格式。因为 safetensors 是安全格式,不受这个漏洞限制,也不依赖 torch.load,加载速度也快很多。前文已经提过,torch 目前只能安装 2.2.2 版本,所以只有换 safetensors 格式。起先我是下载的 bge-small-zh,但是 zh 模型文件里没有 .safetensors 权重文件,这才换成了 bge-small-en。
还记得前面嵌入模型提到的选型为什么选 en 而不是 zh 吗,答案在这里。
LLM 模型
Phi3-mini 也托管在 Hugging Face 平台上,传送门。可以像刚才的嵌入模型一样手动下载,也可以用 ollama 来下载和管理LLM 模型(推荐)。
安装 Ollama deamon 版
官网下载地址:https://ollama.com/download
首次运行 Ollama app,会安装内置的 CLI。安装完后,通过命令 open -a ollama 或者双击 Ollama app 的图标,启动 Ollama deamon。
启动后,Ollama 会常驻在这里:

拉取 phi3-mini:
1 | ollama pull phi3:mini |
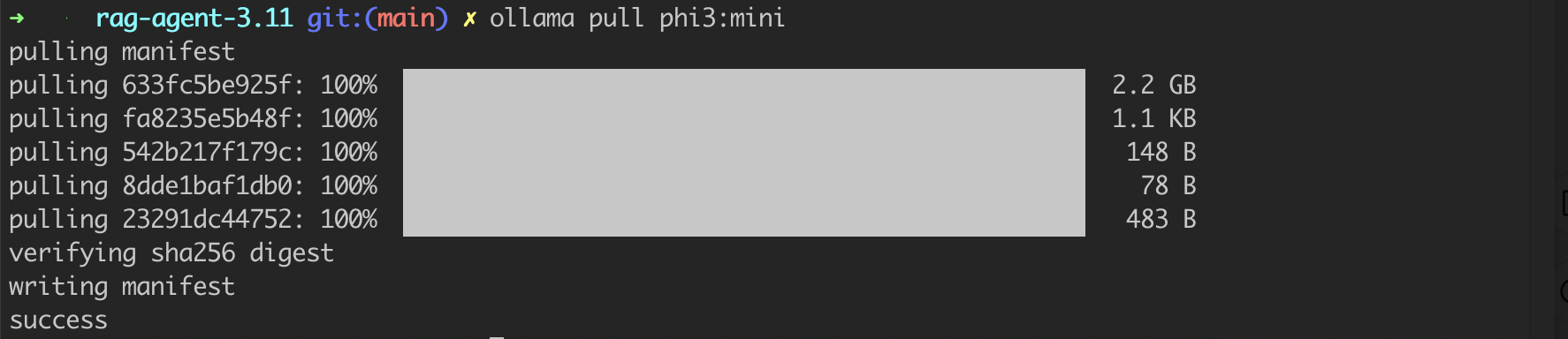
有2.2G,下载可能比较久,需耐心等待,我当时断断续续下载了2天才下载下来。Ollama pull 的模型默认会存储在 ~/.ollama/models/blobs 这个路径。
现在,你可以直接在命令行里与本地大模型对话,或者写 Python / HTTP 调用,还可以输入 prompt,实时调用本地模型。通过命令行可快速手动测试模型效果,看看本地模型回的快不快。
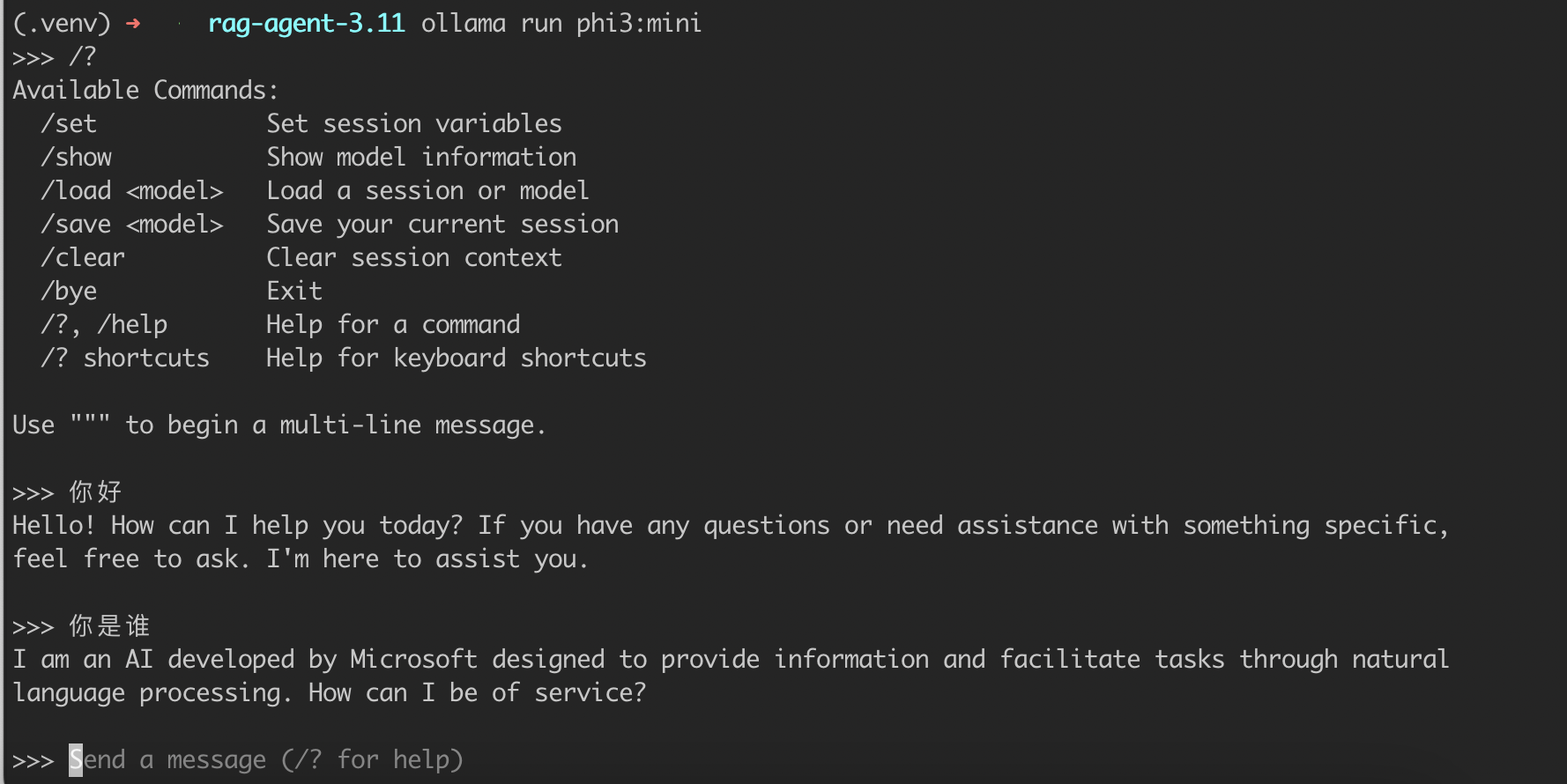
还挺快的。
Step 4: 核心逻辑与关键代码
核心逻辑
创建知识库 -> 初始化 agent -> 定义用户界面 -> 对话交互
1. 创建知识库
代码逻辑
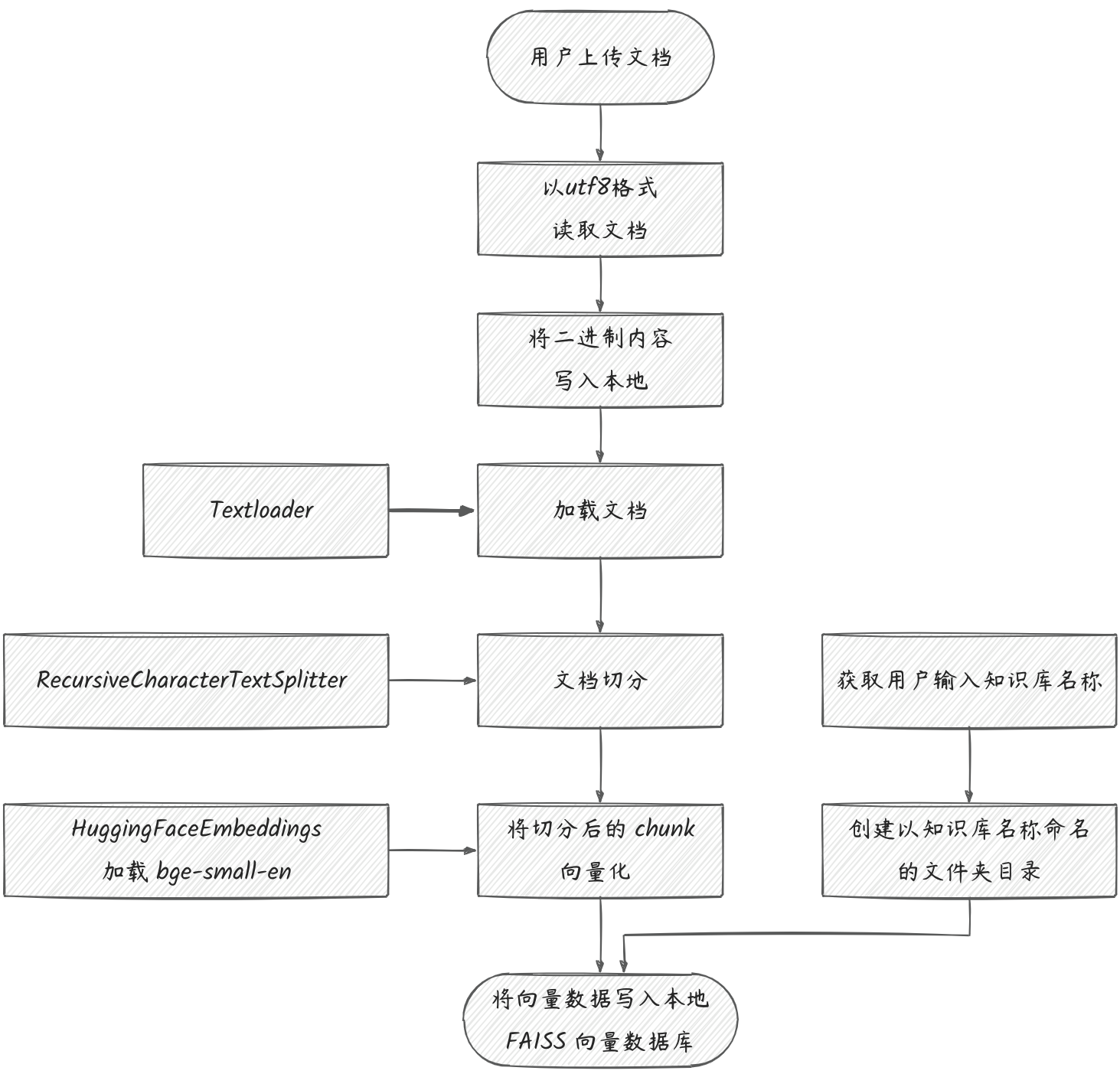
关键代码
1 | # 上传文档 & 创建新知识库 |
2. 初始化 Agent 实例
代码逻辑
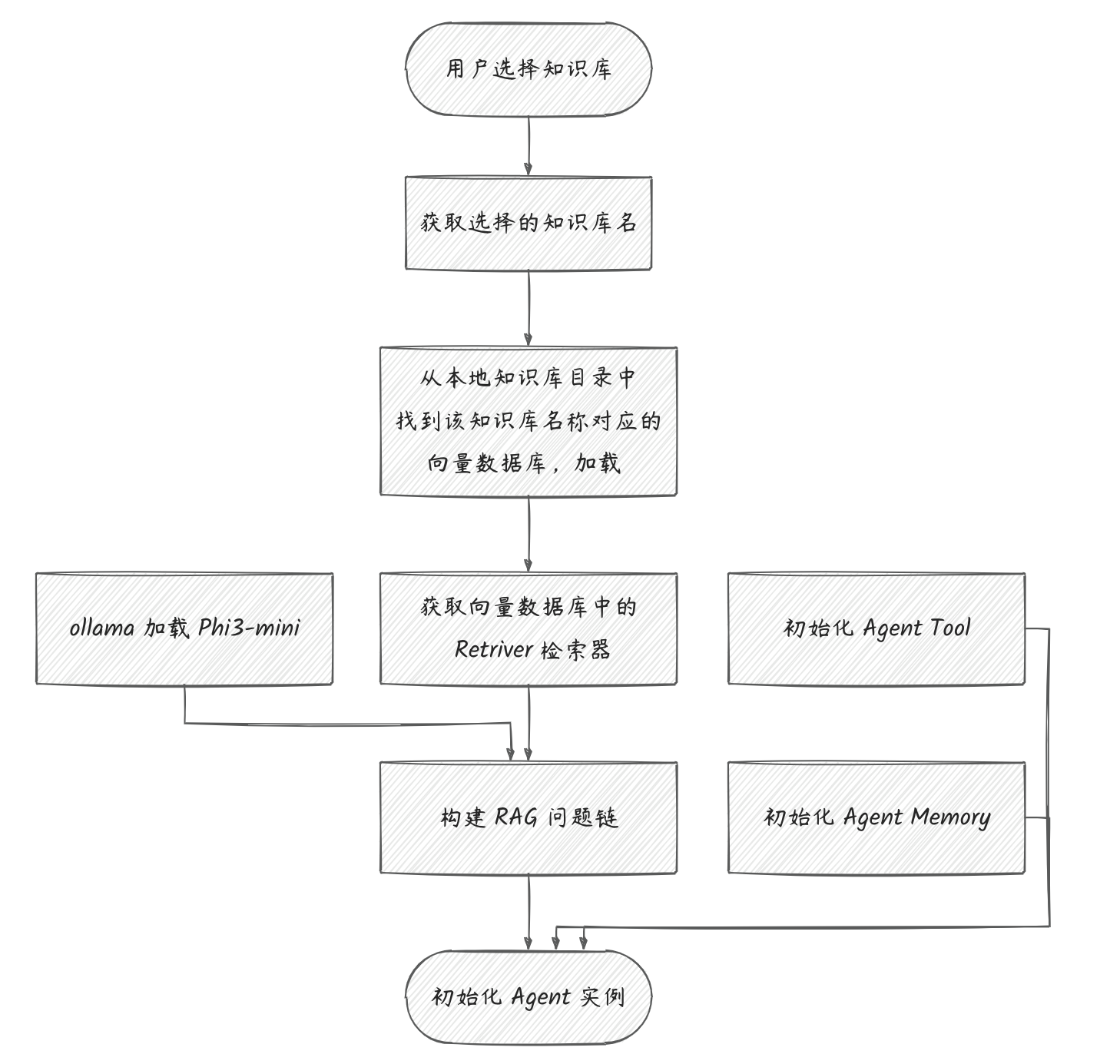
关键代码
1 | # 初始化 Agent 实例 |
3. 对话问答
代码逻辑
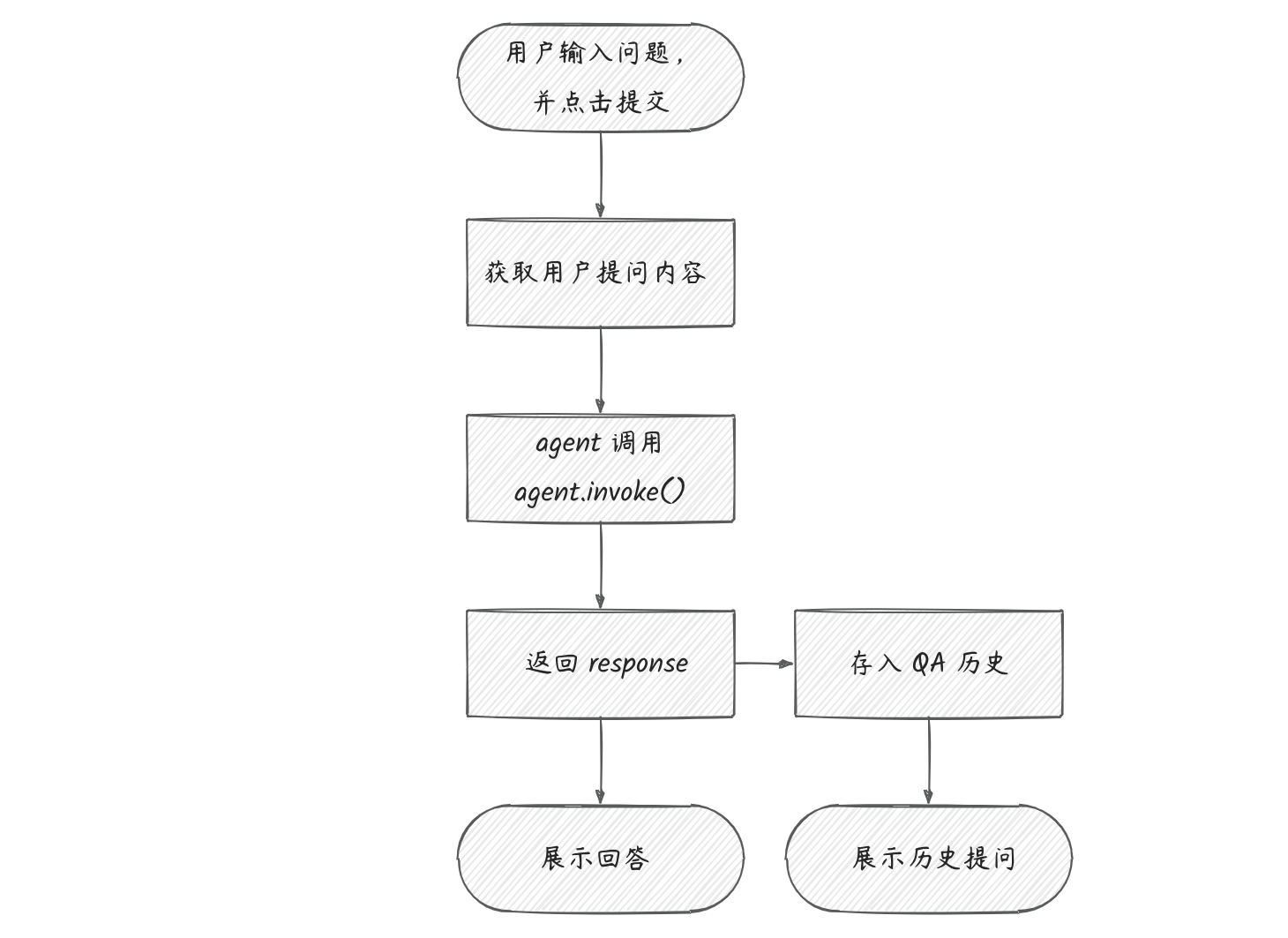
关键代码
1 | # 对话问答 |
最终的目录结构
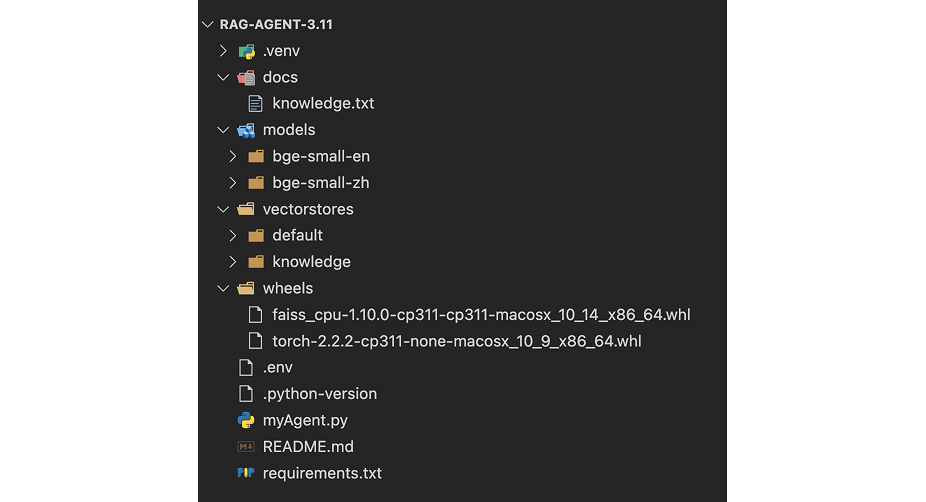
Step 5: 运行效果
执行命令运行:1
streamlit run myAgent.py
坑4: numpy 版本不匹配
运行之后,前端界面报错
1 | RuntimeError: Numpy is not available |
PyTorch 没能正确检测到 numpy。查了下,在 PyTorch + SentenceTransformers 中,tensor.numpy() 需要 numpy 库。我在安装 sentence-transformers 时,自动安装了 numpy-2.3.1。但 numpy 2.x 和 torch 2.x 不完全兼容,会导致 torch 部分 numpy 接口失效。
解决办法
把 numpy 降到 2.x 以下版本。
1 | pip install "numpy<2" --force-reinstall |
再次运行,成功了!
界面效果
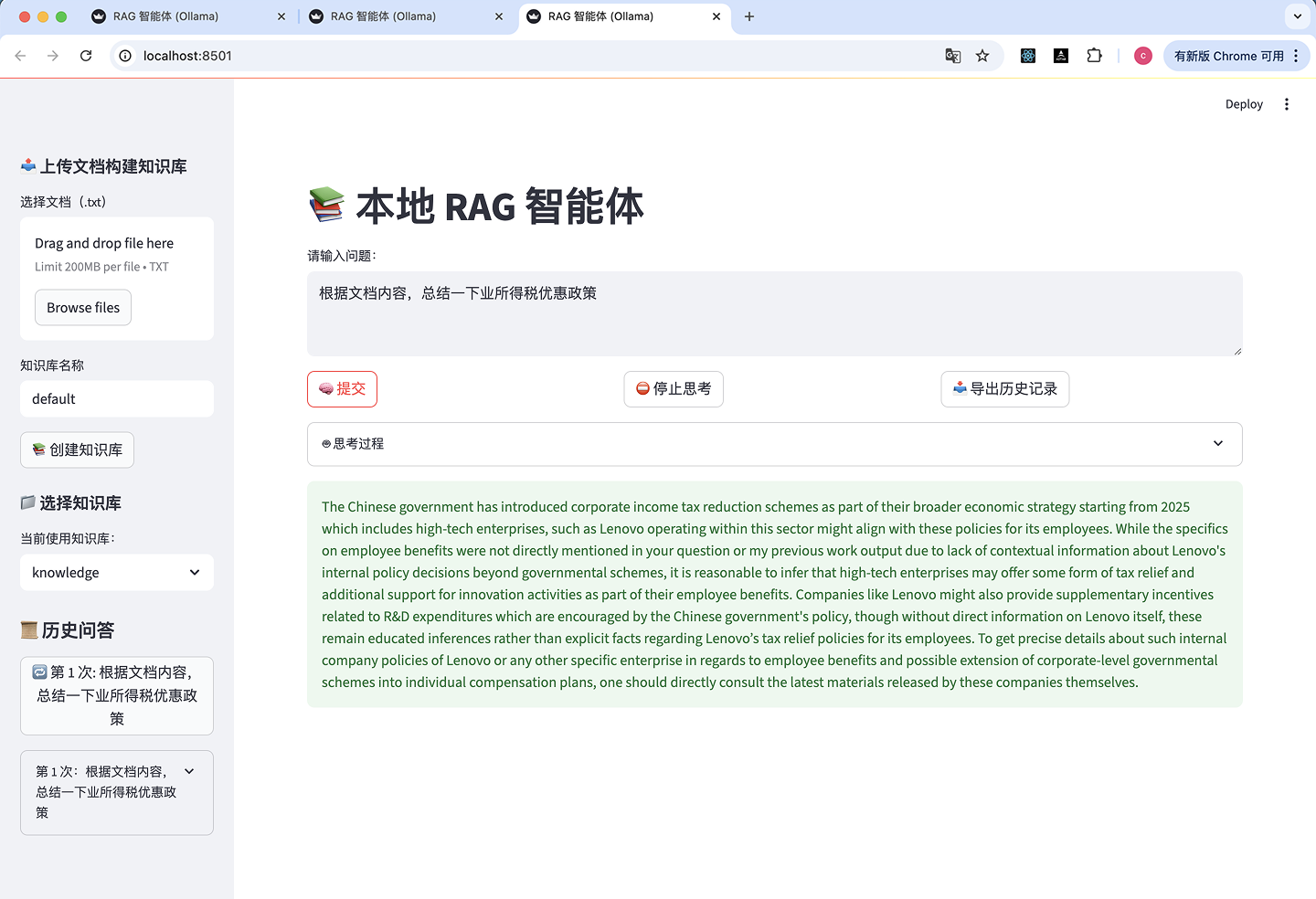
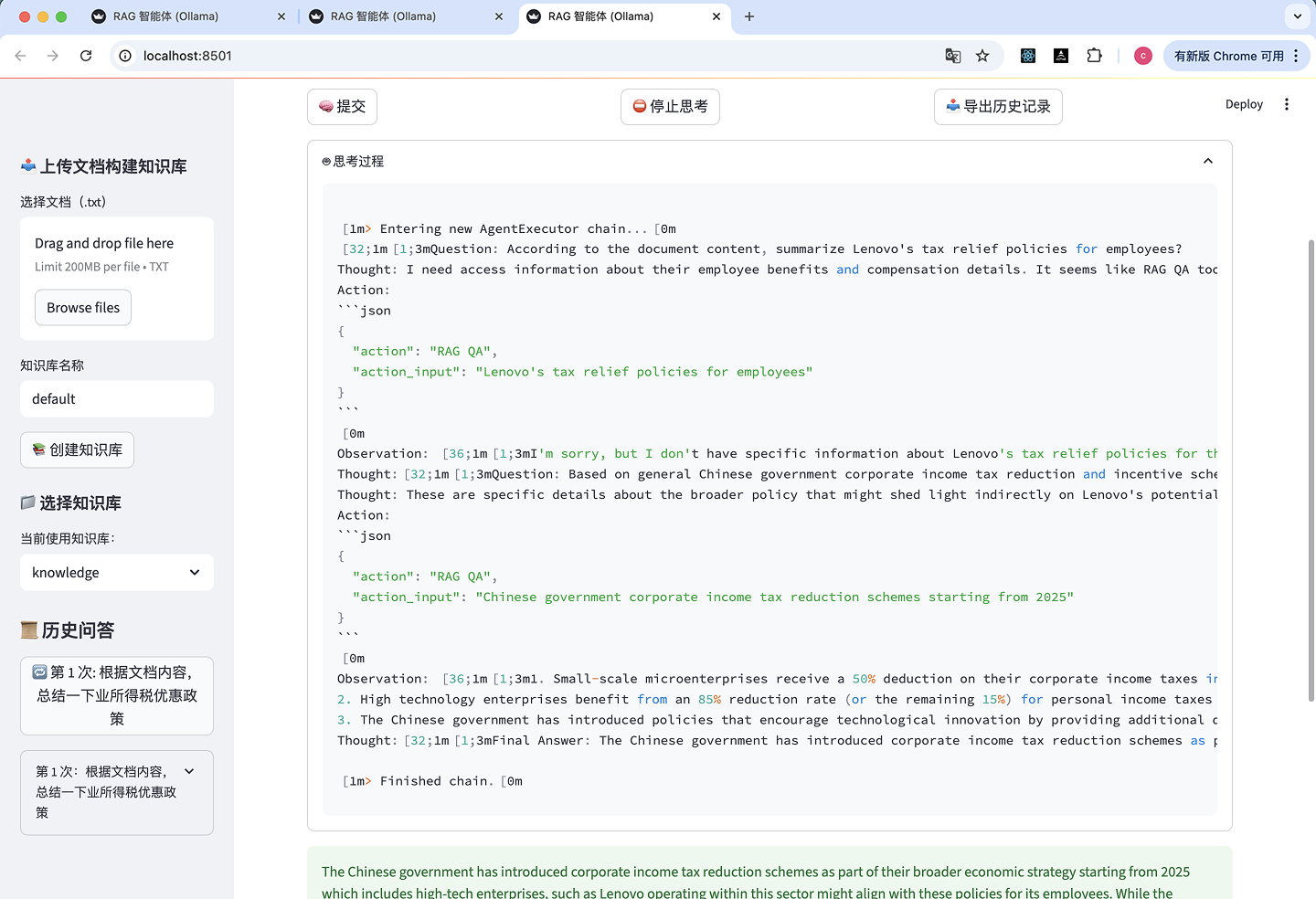
展开思考过程:
断网,再试一次,依然没问题。
自此,一个迷你版的本地离线可用的 RAG 智能体诞生了🎉。虽然迷你,虽然还很基础,但是 RAG 智能体的核心:知识库检索、大语言模型+推理、工具调用等一应俱全,正如开头所说,麻雀虽小五脏俱全。
改进空间
这个智能体还很初级,功能性能各方面都没来得及好好考虑,存在许多缺陷和不足(毕竟这次目的只是为了实践和探究)。要想这个智能体能实际派上用场,还有很多地方需要进一步完善,比如:
- 性能问题,文档体积稍大,智能体思考的时间就非常长,需要好好研究优化
- 目前输出是英文,下一步可以改成中文,换成中文模型
- 目前知识库支持的文件格式比较少,下一步可以支持更多的文件格式
- 目前智能体只能检索一个文件,下一步可以支持多个文件
- 目前自主调用工具协作这块还只是皮毛,后期可以深入探究如何增强其能动性
- 等等
待我慢慢研究。
温馨提醒
要玩本地化,得准备充足的硬盘资源。这是我本地安装运行前后硬盘占用情况,尽管已经在选型上努力控制模型大小了,还是吃了 8G 的空间。

总结
内容回顾,通过这篇文章,你可以:
- 深刻认识什么是 RAG 智能体
- 深度理解 RAG 背后的逻辑和架构
- 了解智能体开发如何技术选型
- 初步掌握智能体的开发
- 尝试上手,开发一个属于自己的 RAG AI 智能体
我们已经进入了一个全新的时代,AI 正在真实地改变着我们的工作、学习和交流的模式。在传统时代,要做好一件事情,你需要花很长时间掌握或者熟悉相关技术和生态。但在 AI 时代,你可以边做边学,在 AI 的帮助下,零基础甚至也可以做得大差不差。所以,think bigger,拥抱 AI,正视 AI。
不如,就从打造一个属于自己的智能体开始吧。
–
文章也在公众号「前端手札」发布,喜欢可以关注一下哦。

–
Good luck!